Why not Linear Regression ?
Imagine that a response is qualitative. Then Linear Regression (Simple Linear Regression) does not perform as well as it does for quantitative for at least two reasons:
- If a response has more than 2 possible values, then we have problem of ordering them or assigning a dummy variable for each. For example, if medical diagnosis can have 3 responses (headache, fever, and drug overdose), then how can we assign a dummy variables like 1,2,3 to each of them? Why not 1,2, and 23? See the problem?
- Even if we have two possible response values(0 and 1), then still it’s not that simple. The linear regression can output out of range , then how do we interpret it? It would be cool to have a function that outputs only between and fit the data to it.
Logistic Regression
Logistic Regression models the probability of the response falling into one of the two categories. That’s why it always outputs .
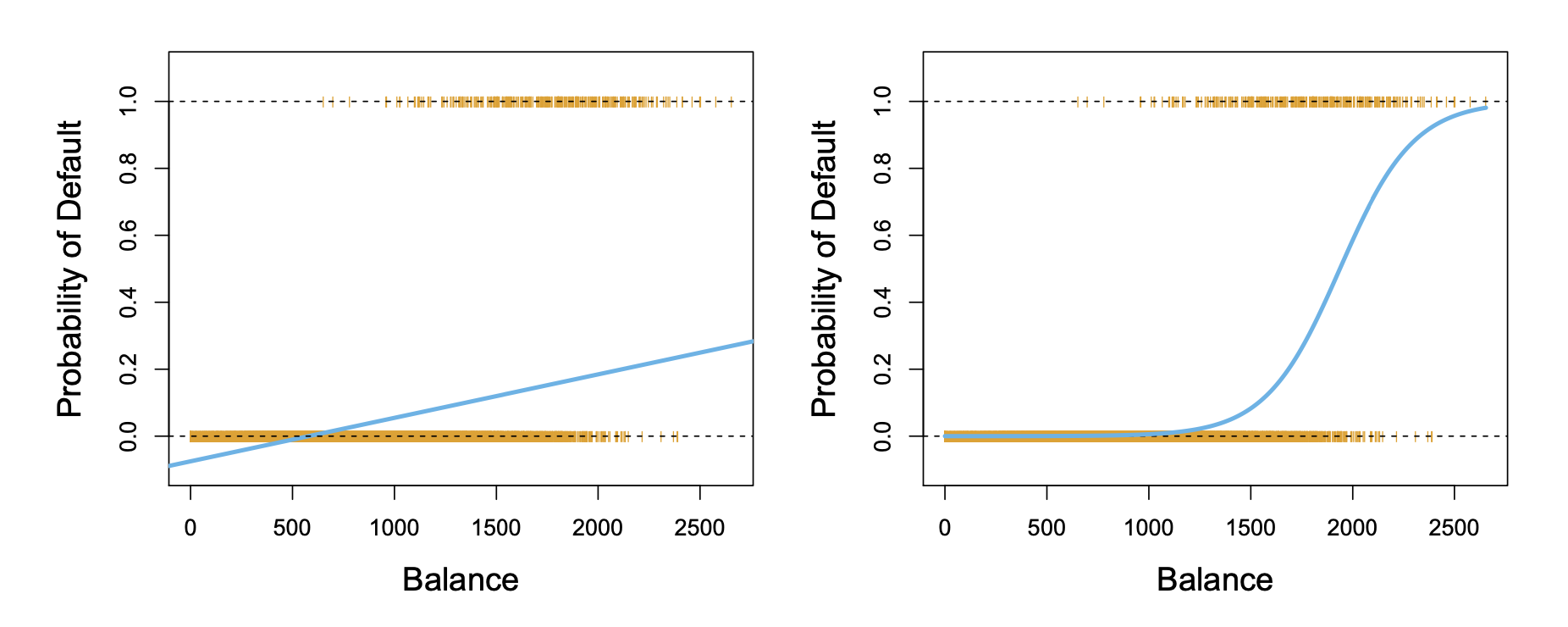
We use the logistic function (s-shaped):
For example, given (bank balance account), we might predict , probability of defaulting. The coefficients are estimated by maximum likelihood. We search for betas such that the result we observe (training data) is the most probable. For the binary case, mathematically we try to maximize the function:
As we can see we assume that the events are independent.
Multiple Regression : It’s not that complicated to guess the form of multiple linear regression: we just add some terms to the power of the exponent.
Generative Models for classification
We can use a cool trick, Bayes’ theorem, to flip cards around. For instance, let’s assume we have classes. Then we can define a function . What this says is that given Y falls into kth bin, we can find the probability that . Then Bayes’ theorem states that
(1) State the difference between Bayes classifier and Bayes’ theorem. Two absolutely different things. The problem now arises with finding the …
LDA for p = 1
One way to do it is use LDA (linear discriminant analysis). (2) What are its main assumptions? Paste the picture of derivation …
For the cases where , we assume multivariate Gaussian. Long story short, everything is sort of similar to p=1, but just in multiple dimensions with matrices and vectors. Nothing that much complicated (LUL).
QDA
The main difference between LDA and QDA is that the latter does not assume identical covariance matrices for all predictors. Basically, each multidimensional Gaussian has its own unique variance/deviation. From that it attains an additional x-term quadratic in the name.
Why not use QDA always since it’s more general method? The answer is again Bias-Variance Trade-off ! (3) At this point you tell me which model is more flexible, has higher variance and bias.
Naive Bayes
The problem we face is modeling p-dimensional density function for each class, which is a hard task. LDA and QDA assumed that these belong to particular family of function (normal). In Naive Bayes, however, we make a different assumption: within classes, all predictors are independent!:
where each function is single variable: function of the jth predictor on kth class. Now, instead of one p-dimensional problem, we deal with p one-dimensional problems! And here we can once again assume that each function is normal, non-parametric, or qualitative.
Answers
- asdasd
- First, we assume that is Gaussian and second that standard deviations for each class are identical.
- Obviously (never thought I would start an explanation like that), QDA is more flexible than LDA, and thus has less bias. But this means it depends more on the test data set, which leads to higher variance. Generally, use QDA when an assumption of common covariance matrix might be off or when the data set is large.