My notes while completing the ARENA exercises on Sparse Autoencoders (SAEs).
Intro to SAE Interpretability
Dashboard Visualizations provided by Neuronpedia are quite useful. They have 5 parts: Latent activation distribution, logit distribution, top/bottom logits, max activating examples, and autointerp. An example is shown below
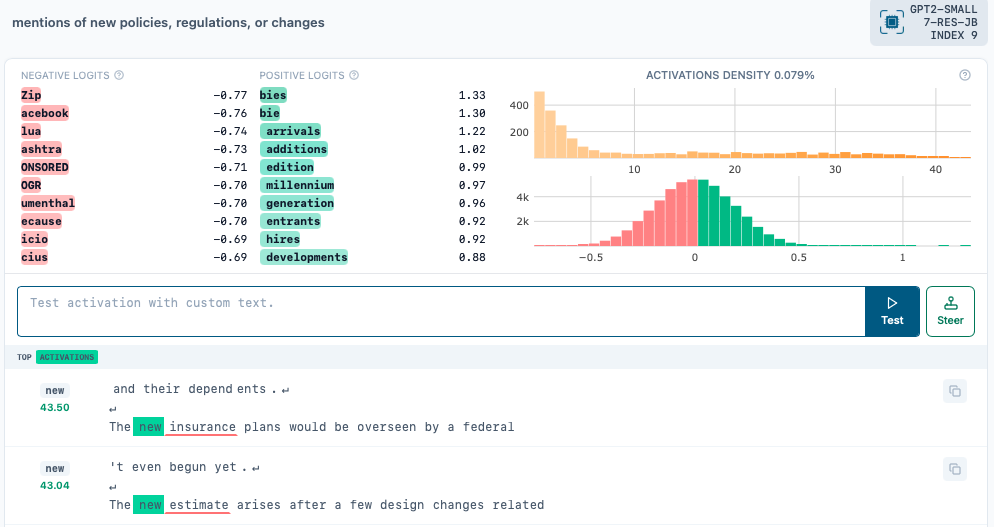
This latent with index 9 mostly fires when something new is mentioned. It seems to be a token-level feature because it mostly activates for a single token new and has sparse activation density (0.079%).